Summarizing Scientific Articles
-
Strategy for the summarization of scientific articles that concentrates on the rhetorical status of statements in an article: Material for summaries is selected in suchway that summaries can highlight the new contribution of the source article and situate it with respect to earlier work.
-
An algorithm that, on the basis of the annotated training material, selects content from unseen articles and classifies it into a fixed set of seven rhetorical categories. The output of this extraction and classification system can be viewed as a single-document summary.
Data Format
<PAPER>
<TITLE> Similarity-Based Estimation of Word Cooccurrence Probabilities </TITLE>
<AUTHORLIST>
<AUTHOR>Ido Dagan</AUTHOR>
<AUTHOR>Fernando Pereira</AUTHOR>
<AUTHOR>Lillian Lee</AUTHOR>
</AUTHORLIST>
<ABSTRACT>
<A-S ID='A-0' AZ='BKG'> In many applications of natural language processing it is necessary to determine the likelihood of a given word combination . </A-S>
</ABSTRACT>
<BODY>
<DIV DEPTH='1'>
<HEADER ID='H-0'> Introduction </HEADER>
<P>
<S ID='S-0' AZ='BKG'> Data sparseness is an inherent problem in statistical methods for natural language processing . </S>
</P>
</DIV>
</BODY>
<REFERENCELIST>
<REFERENCE>
<SURNAME>Sugawara</SURNAME>, K., M. <SURNAME>Nishimura</SURNAME>, K. <SURNAME>Toshioka</SURNAME>, M. <SURNAME>Okochi</SURNAME>, and T. <SURNAME>Kaneko</SURNAME>.
<DATE>1985</DATE>.
Isolated word recognition using hidden Markov models.
In Proceedings of ICASSP, pages 1-4, Tampa, Florida. IEEE.
</REFERENCE>
</REFERENCELIST>
</PAPER>
- annotated data is present in xml format.
- iterate through each tag and extract relevant feature information.
FeatureGenerator.py
from FeatureGenerator import FeatureGenerator
# locate corpus data
xmlcorpora = "../data/corpora/AZ_distribution/"
# generate gold-standard features
featureGen = FeatureGenerator(xmlcorpora)
# sample feature vectors
# featureGen.features[<xmlfile_name>][<line_ID>]
# example
print featureGen.features["9405001.az-scixml"]["A-0"]
- generates features from parsing XML paper format
- each sentence has 14 features along with a tag, stored in
self.featuresin FeatureGenerator object - Implemented features capture
- absolute location
- Tf-Idf scoring
- history
- citations & references
- title & length
- explicit structure
NaiveBayes.py
from FeatureGenerator import FeatureGenerator
from NaiveBayes import NaiveBayes
# locate corpus data
xmlcorpora = "../data/corpora/AZ_distribution/"
# generate gold-standard feature vectors
featureGen = FeatureGenerator(xmlcorpora)
# initialise and train NB model
classifer = NaiveBayes(features=featureGen.features, distribution="Bernoulli", train_split=0.8)
classifer.train()
# Analysis
confusionMatrix, precisionRecallF1, accuracy = classifer.test()
classifer.plotConfusionMatrix(confusionMatrix, range(8))
print("=== Accuracy: %f ===" %(accuracy))
# generate summary
classifer.getSummary('9405001.az-scixml')
- gets the feature vectors of each sentence from FeatureGenerator object
- trains with different classifer as choosen
distribution="Bernoulli", available options include- Compliment
- Bernoulli
- Multinomial
- Gaussian
- Deep
- Implemented classifiers
- Gaussian Naive Bayes (acc: 25%)
- Multinomial Naive Bayes (acc: 72%)
- Bernoulli Naive Bayes (acc: 80%)
- Compliment Naive Bayes (acc: 73%)
- Deep CNN Network (acc: 71%)
clean.py
python clean.py inputFile | awk '!uniq[substr($0, 0, 10000)]++' > outFile
- Basic cleaning of the
inputFileand writing tooutFile, each line inoutFilebeing a sentence from theinputFile. - May have errors, ignore them or manually correct if you want.
script.py
python script.py inputFile outFile annotationFile
- Send the
inputFile(output ofclean.py). - Each line from the
inputFilepops up and you will be asked to tag it. - The details of the key for each tag will be output under each sentence.
- Enter the corresponding tag and that line will be appended to
outFileand your tag to theannotationFile. - Used RECHECK(R) tag incase you are not sure about it. Do it manually later, etc.
- Used IGNORE(I) tag incase that sentence is trash and is not cleaned well from
clean.pyfile. - The line and the tag wont be written incase of IGNORE tag.
Plots
- set of true positive/negative & false positive/negative classification plots using confusion matrix
- classifier prediction distribution plots using histograms ### Confusion Matrix
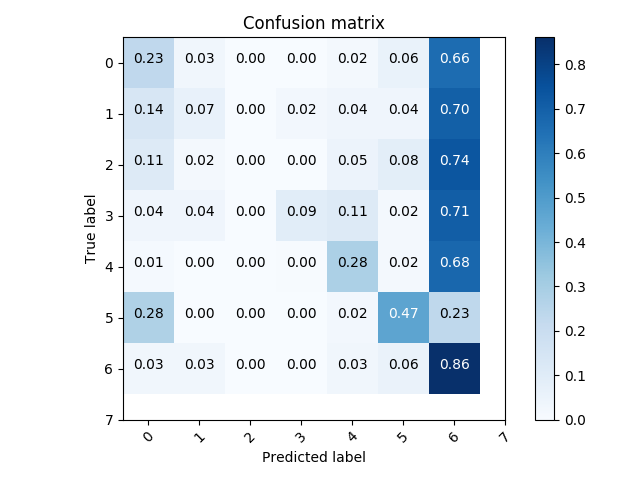
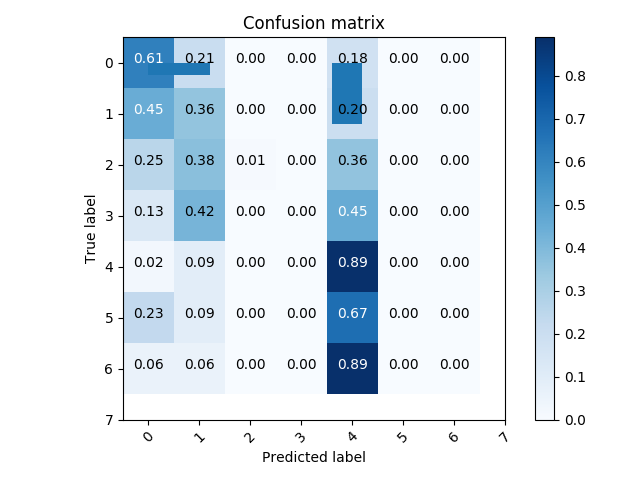
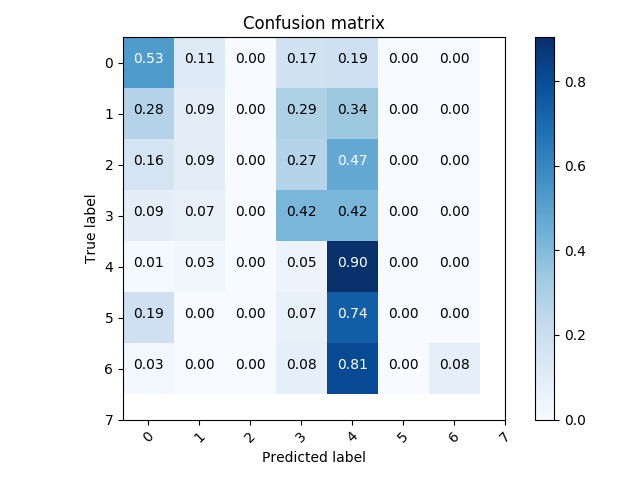
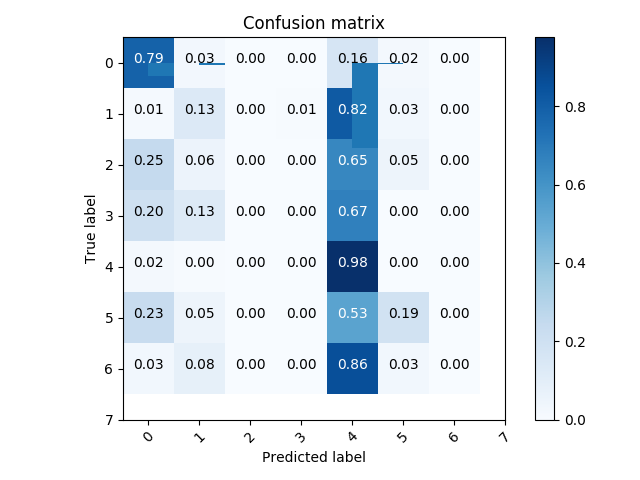 ### Histograms
### Histograms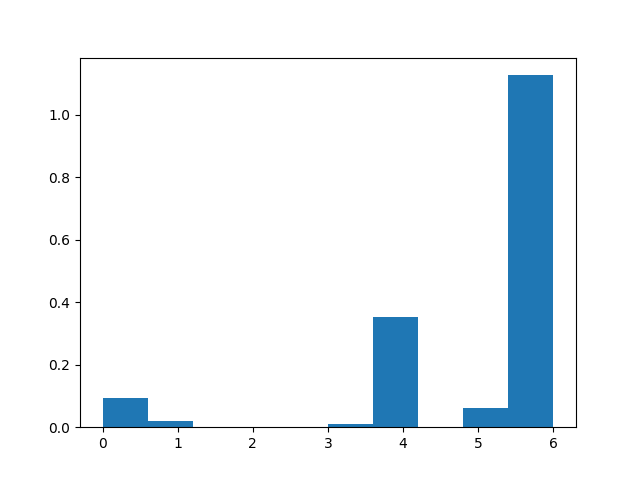
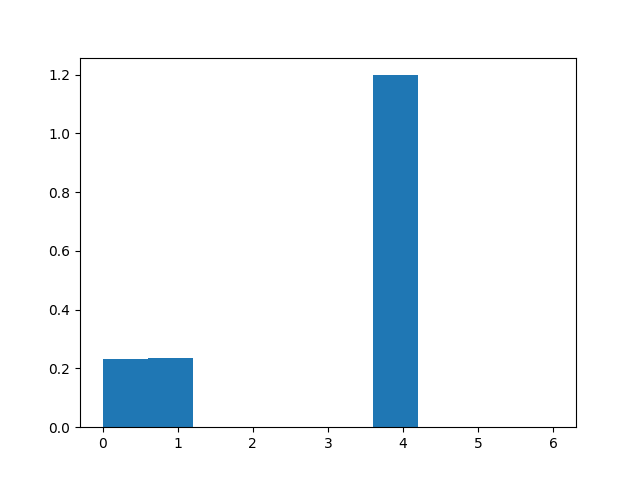
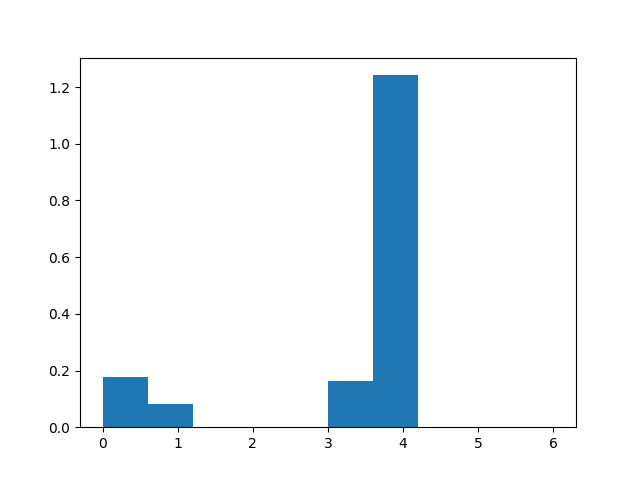
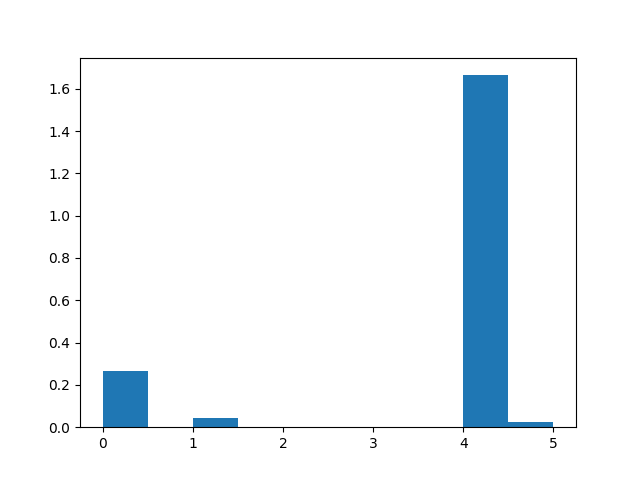
Dependencies
# matplotlib
pip install --user matplotlib
# numpy
pip install --user numpy
# nltk
pip install --user nltk
# scikit-learn
pip install --user scikit-learn
# tensorflow
pip install --user tensorflow
# gensim
pip install --user gensim
# keras
pip install --user keras